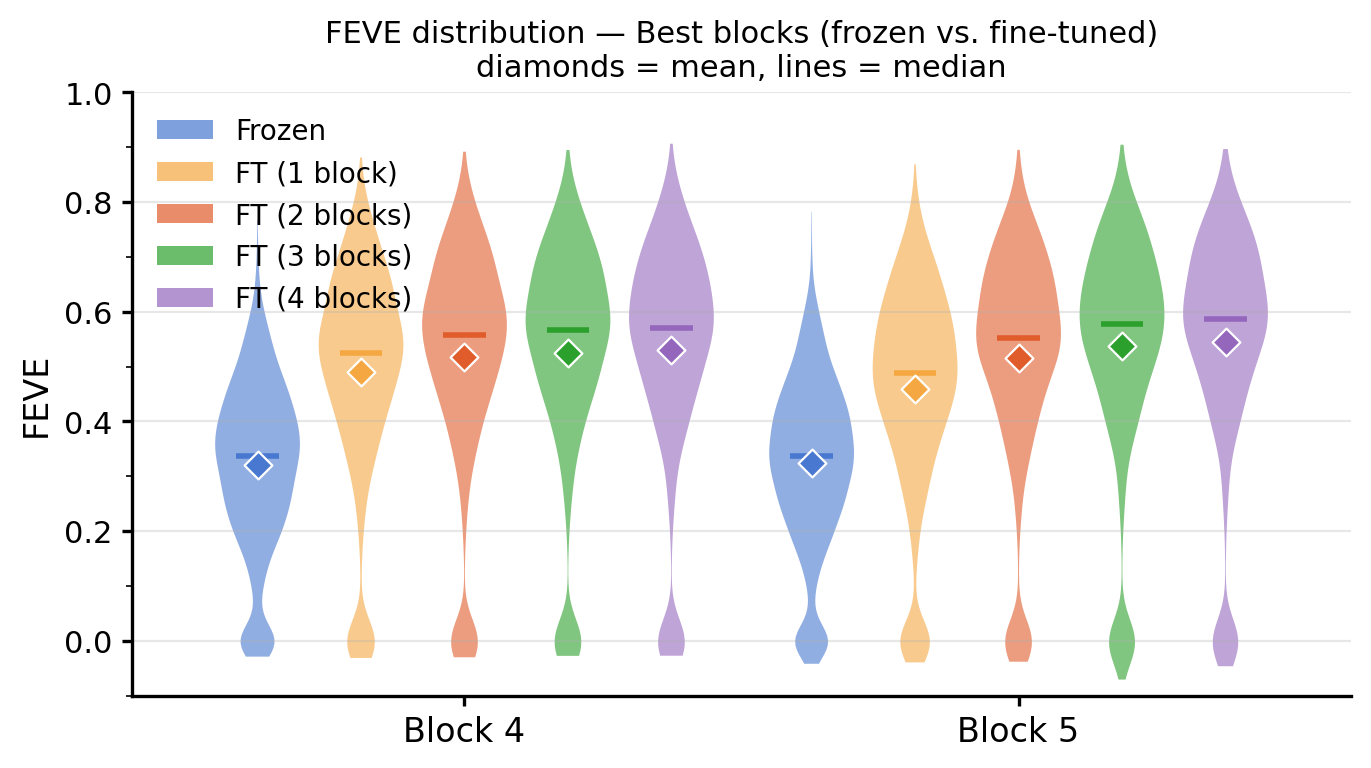
Can frozen or fine-tuned Vision Transformers replace task-optimized CNNs for predicting neural responses in mouse primary visual cortex? A follow-up to the minimodel paper.
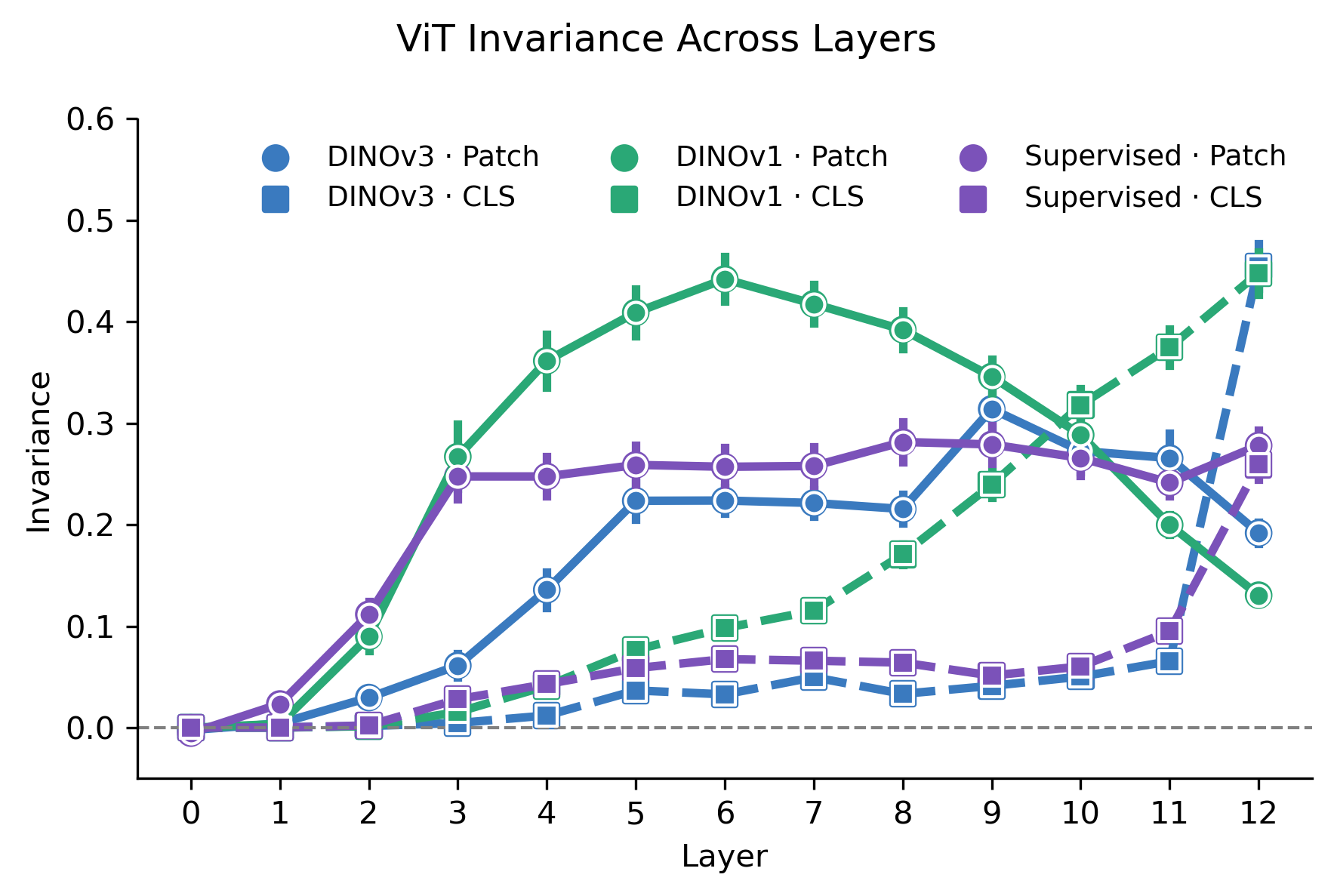
Comparing how CNN and ViT architectures shape representational invariance across layers, with the goal of understanding how artificial visual systems relate to biological ones.
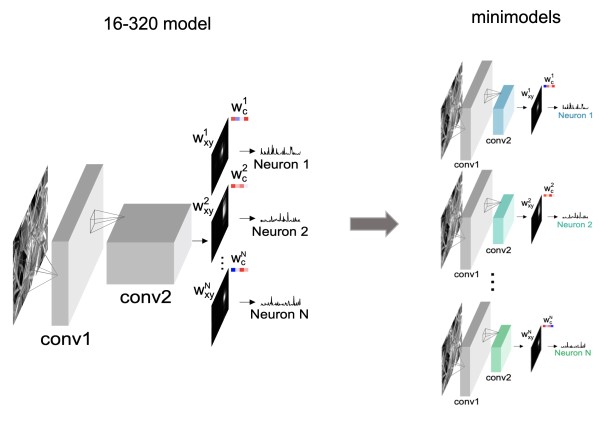
Simplified and interpretable “minimodels” are sufficient to explain complex visual responses in mouse and monkey V1.
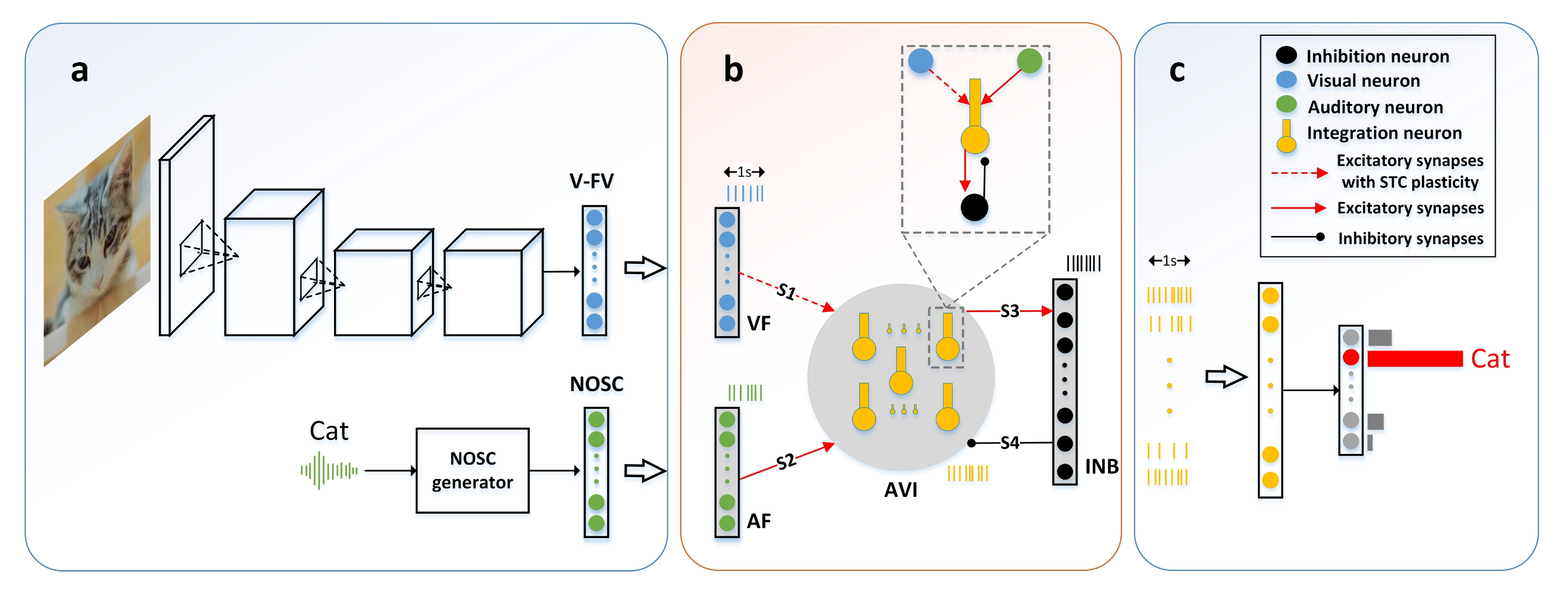
AVIM is a multimodal spiking model that fuses visual and audio inputs and learns with a Synaptic Tagging & Capture–like rule. It targets brain-inspired continual learning with reduced catastrophic forgetting.
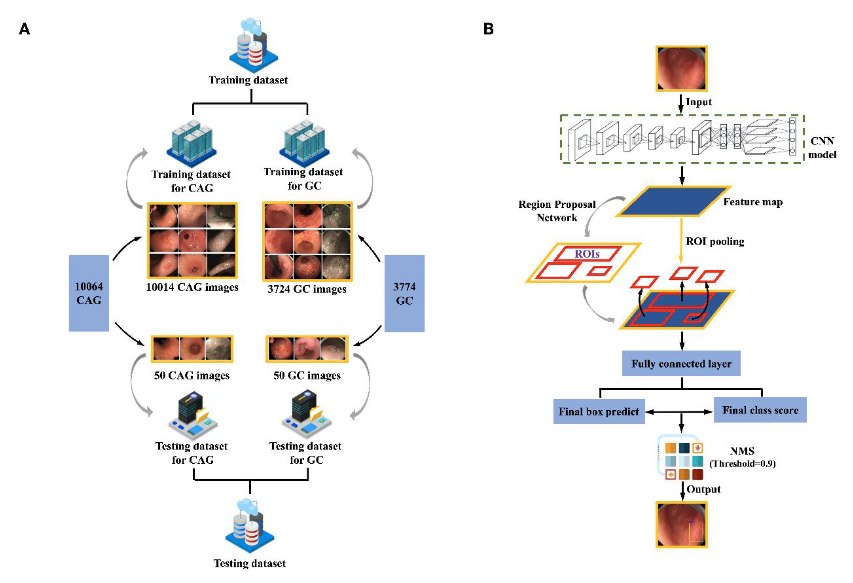
Digestive Endoscopology Recognition.
Object detection from basketball and football videos.
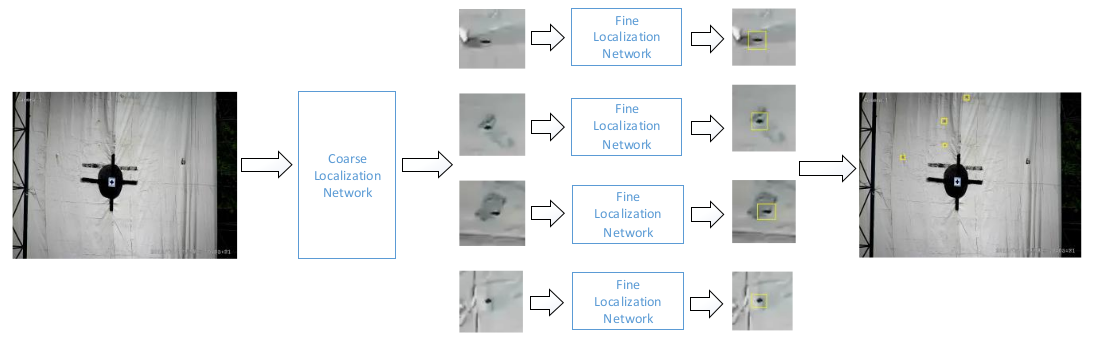
Bullet hole detection using series Faster-RCNN and video analysis.
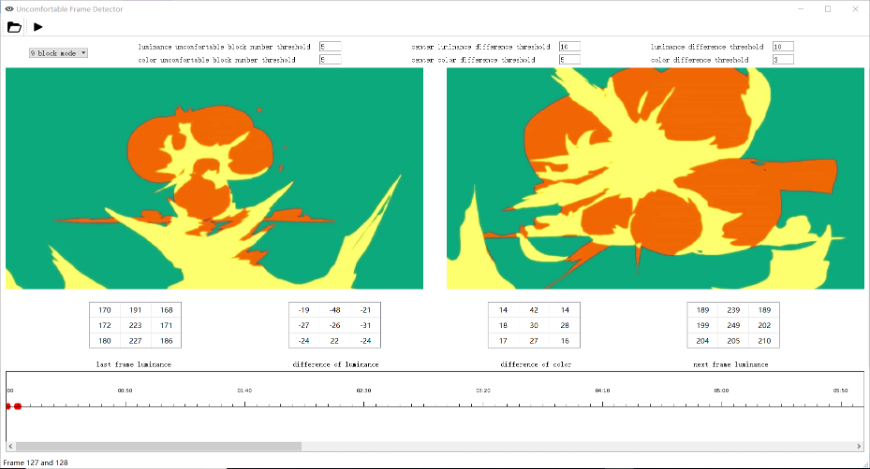
A Python tool that quantifies visual comfort in video and image sequences by detecting jarring luminance transitions across frames.