Encoding Mouse V1 with Vision Transformers
Can frozen or fine-tuned Vision Transformers replace task-optimized CNNs for predicting neural responses in mouse primary visual cortex? A follow-up to the minimodel paper.
Motivation
The minimodel paper established that compact two-layer CNN “minimodels” explain ~70% of neural variance in mouse and monkey V1. A natural follow-up is to ask: can Vision Transformers (ViTs) serve as an equally good — or better — backbone for encoding V1 responses? ViTs are now state-of-the-art on many vision benchmarks and their self-supervised variants (DINO) produce rich, invariant representations. However, their patch-based processing differs fundamentally from the strided convolutions of CNNs, which may matter for neurons with highly localized receptive fields.
Setup
Input preprocessing - 66×264 grayscale images → resized to 64×128, converted to pseudo-RGB, normalized with ImageNet statistics
Backbone - ViT-S/16 (384-dim, ~21M parameters) and ViT-B/16 (768-dim, ~86M parameters), initialized from DINOv2 weights - Features extracted from any of the 12 transformer blocks; both CLS tokens and patch tokens evaluated
Readout - The same minimodel readout from the original paper: separable spatial weights over the patch grid combined with a learned channel mixture — one model per neuron, mirroring the CNN architecture
Training conditions compared - Frozen backbone (no gradient flow to ViT) - Fine-tuning last 2 blocks - Fine-tuning last 4 blocks - Full fine-tuning
Results
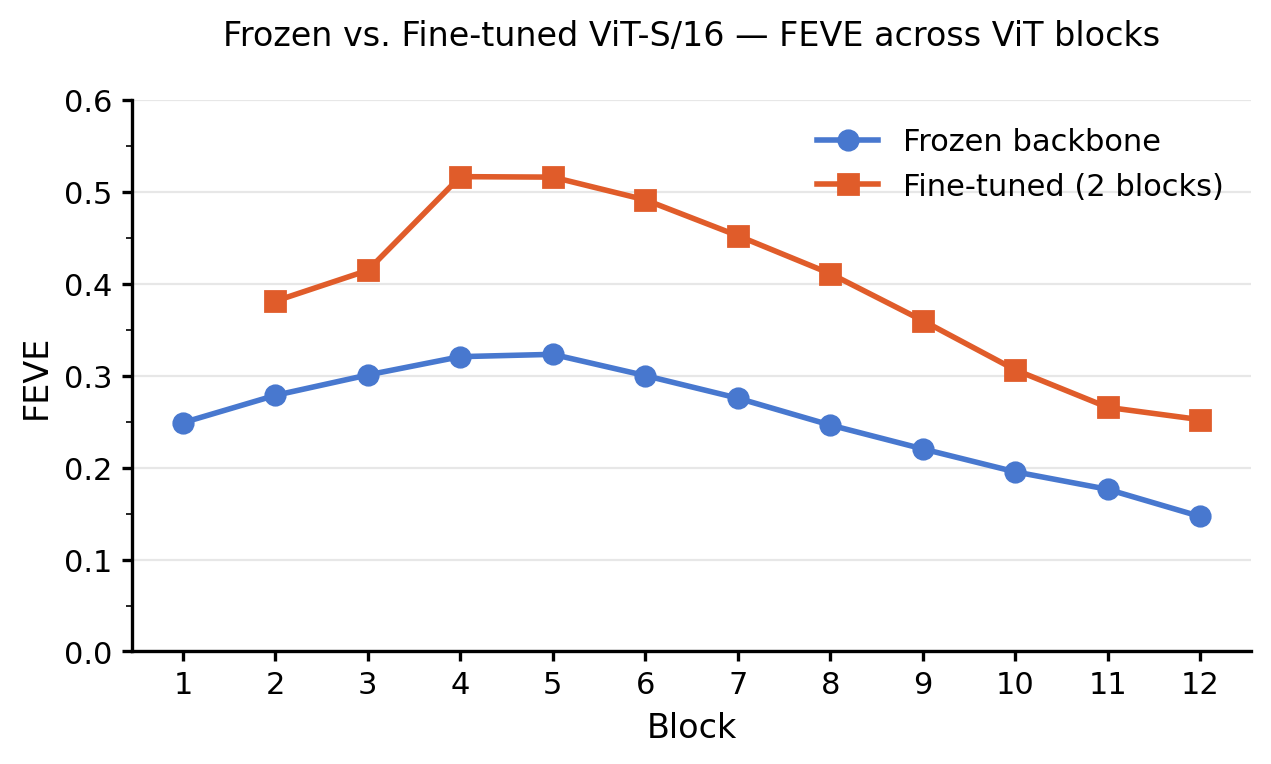
Effect of fine-tuning: frozen vs. last 2 blocks fine-tuned (ViT-S/16)
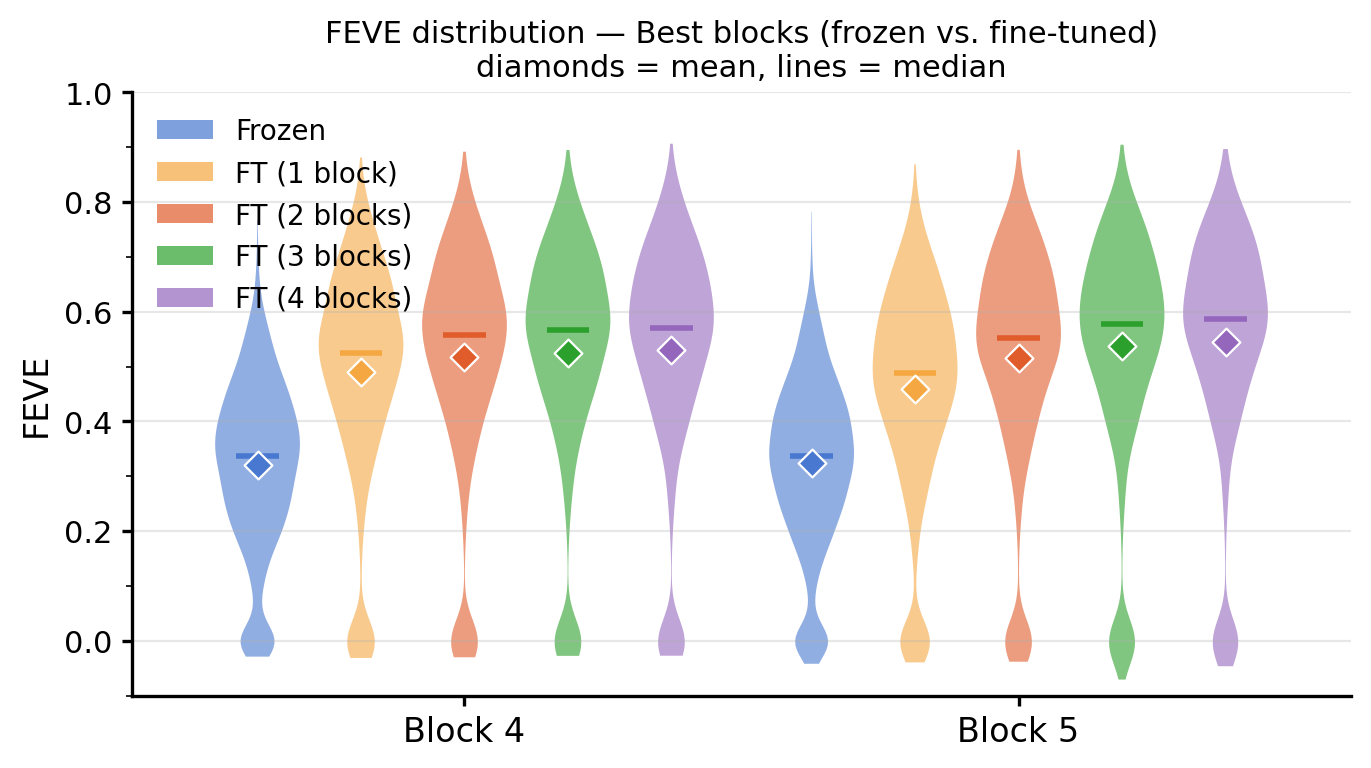
Best-block FEVE across all fine-tuning conditions
| Model | Fine-tuning | Best block | FEVE |
|---|---|---|---|
| CNN fullmodel (baseline) | Full | — | 0.6654 |
| ViT-S/16 | Frozen | 4 | 0.32 |
| ViT-S/16 | Last 2 blocks | 3–4 | ~0.52 |
| ViT-S/16 | Last 4 blocks | 3–4 | 0.5449 |
| ViT-B/16 | Frozen | — | > ViT-S frozen |
| ViT-B/16 | Full fine-tune | — | slightly < ViT-S fine-tuned |
FEVE (Fraction of Explainable Variance Explained) is the primary metric, normalized by the noise ceiling estimated from repeated stimulus presentations.
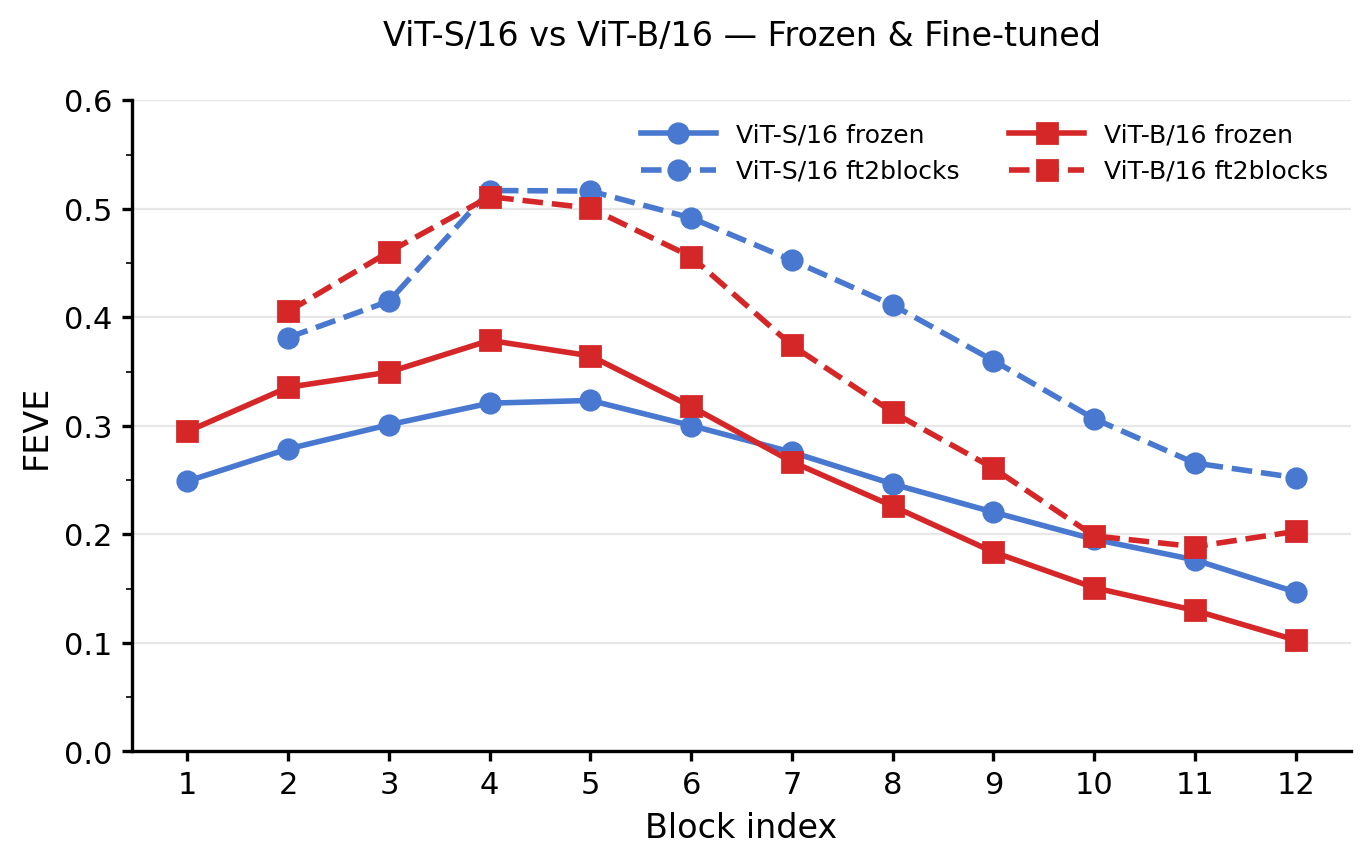
ViT-S vs. ViT-B: frozen and fine-tuned
Key findings
- Fine-tuning is essential. Frozen ViT-S/16 reaches only FEVE = 0.32; fine-tuning the last 4 blocks pushes this to 0.5449 — a 70% gain.
- Smaller models adapt more efficiently. ViT-B/16 surpasses ViT-S/16 in the frozen regime but is slightly worse after full fine-tuning, suggesting that larger models have more parameters to overfit on the limited neural dataset.
- CNNs still lead. The task-optimized CNN fullmodel (FEVE = 0.6654) outperforms all ViT variants, with the gap largest in deeper fine-tuning conditions.
- Spatial resolution is the bottleneck. A 16×16 patch stride on a 64×128 input produces only a 4×8 patch grid — far coarser than CNN feature maps. V1 neurons with precise spatial tuning cannot be well-described by such a grid, which likely explains most of the remaining gap.
Discussion
These results suggest that ViTs are not yet a drop-in replacement for CNNs in V1 encoding models, primarily because of spatial resolution constraints. Future directions include: (1) smaller patch sizes (e.g., ViT/8 or ViT/4); (2) multi-scale or hierarchical ViT variants (e.g., Swin Transformer); (3) combined CNN-ViT architectures that leverage both local and global processing.