Visual Representation Invariance: Comparing CNNs and Vision Transformers
Comparing how CNN and ViT architectures shape representational invariance across layers, with the goal of understanding how artificial visual systems relate to biological ones.
Motivation
How do different model architectures and training objectives shape the geometry of internal representations? This project analyzes the invariance structure across layers in a set of CNNs and Vision Transformers (ViTs), using a controlled texture stimulus set. The broader goal is to understand how these artificial visual representations compare to those in mouse visual cortex — part of an ongoing collaboration with a postdoc in the lab.
Models and stimuli
Six models were compared across the full spectrum of architecture and training paradigm:
| Model | Architecture | Training |
|---|---|---|
| DINOv2 | ViT | Self-supervised |
| DINOv1 | ViT | Self-supervised |
| Supervised ViT | ViT | Supervised (ImageNet) |
| ResNet50 | CNN | Supervised (ImageNet) |
| VGG16 | CNN | Supervised (ImageNet) |
| AlexNet | CNN | Supervised (ImageNet) |
Stimuli: 32 texture images spanning 8 categories (Leaves, Circles, Dryland, Rocks, Tiles, Squares, Rleaves, Paved) — 4 images per category.

Invariance metric
For each layer, we extract hidden representations (CLS tokens or mean-pooled patch tokens for ViTs; pooled feature maps for CNNs) and compute a 32×32 pairwise Pearson correlation matrix. Invariance between two stimuli A and B is defined as:
\[ \text{Invariance}(A, B) = \frac{R_{AA} + R_{BB}}{2} - R_{AB} \]
where R_XY is the average cross-image correlation within category X and Y. High invariance means the model treats two images from the same category as similar while keeping different categories apart — a hallmark of a useful visual representation.
An example correlation matrix for DINOv2 at the final layer:

Key findings
ViTs: self-supervised vs. supervised
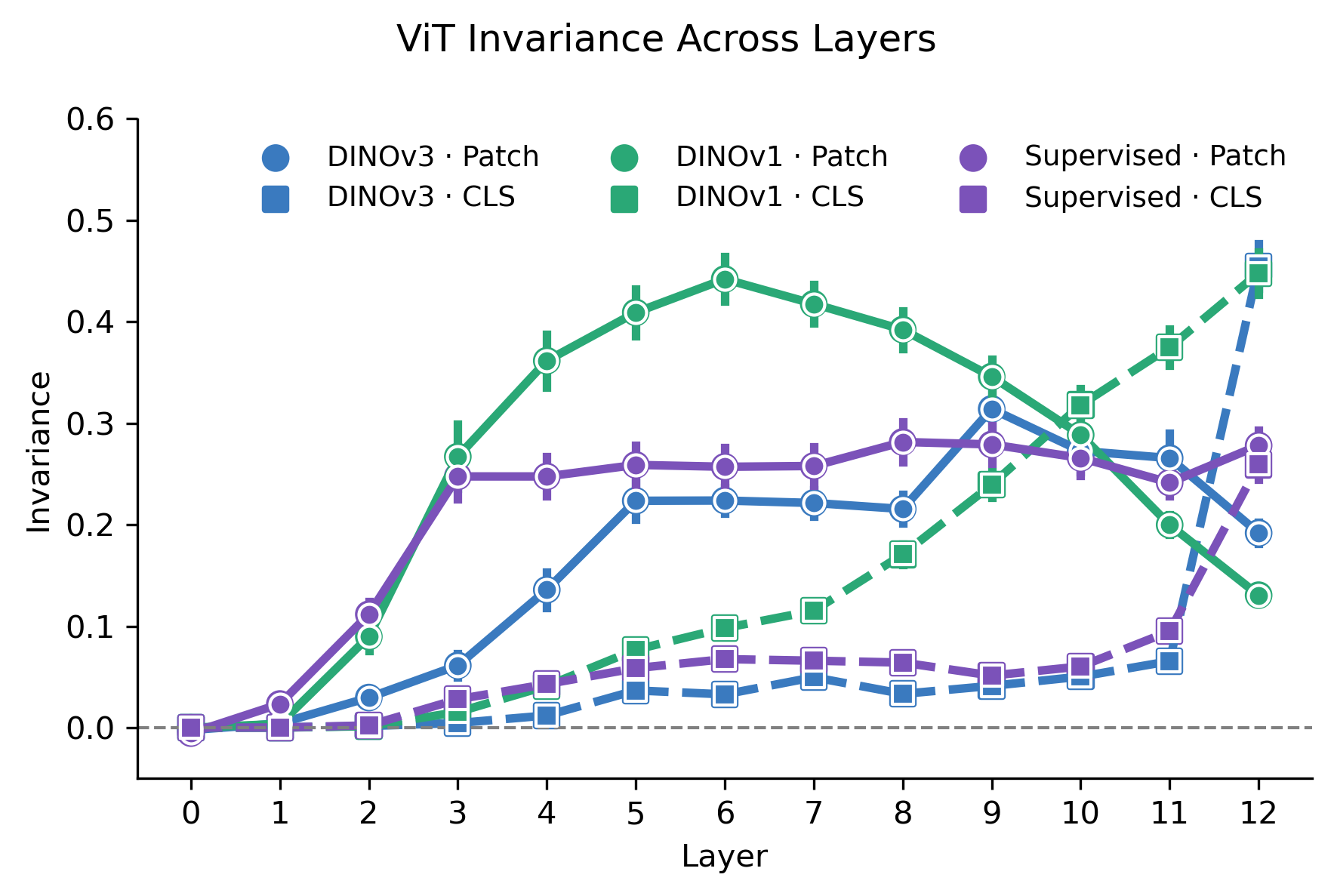
- Self-supervised ViTs build the most invariant representations. DINOv1 and DINOv2 CLS tokens at the final layer are substantially more invariant than those of the supervised ViT, despite never seeing category labels during training.
- DINOv1 patch tokens peak early then decline. Patch token invariance peaks at ~0.44 around layer 6 before falling off, while CLS tokens continue to rise — suggesting the CLS token aggregates category-relevant information progressively.
- Training objective matters more than dataset. The supervised ViT, trained on the same ImageNet data as the CNNs, produces lower final-layer invariance than its self-supervised counterparts.
CNNs: monotonic buildup
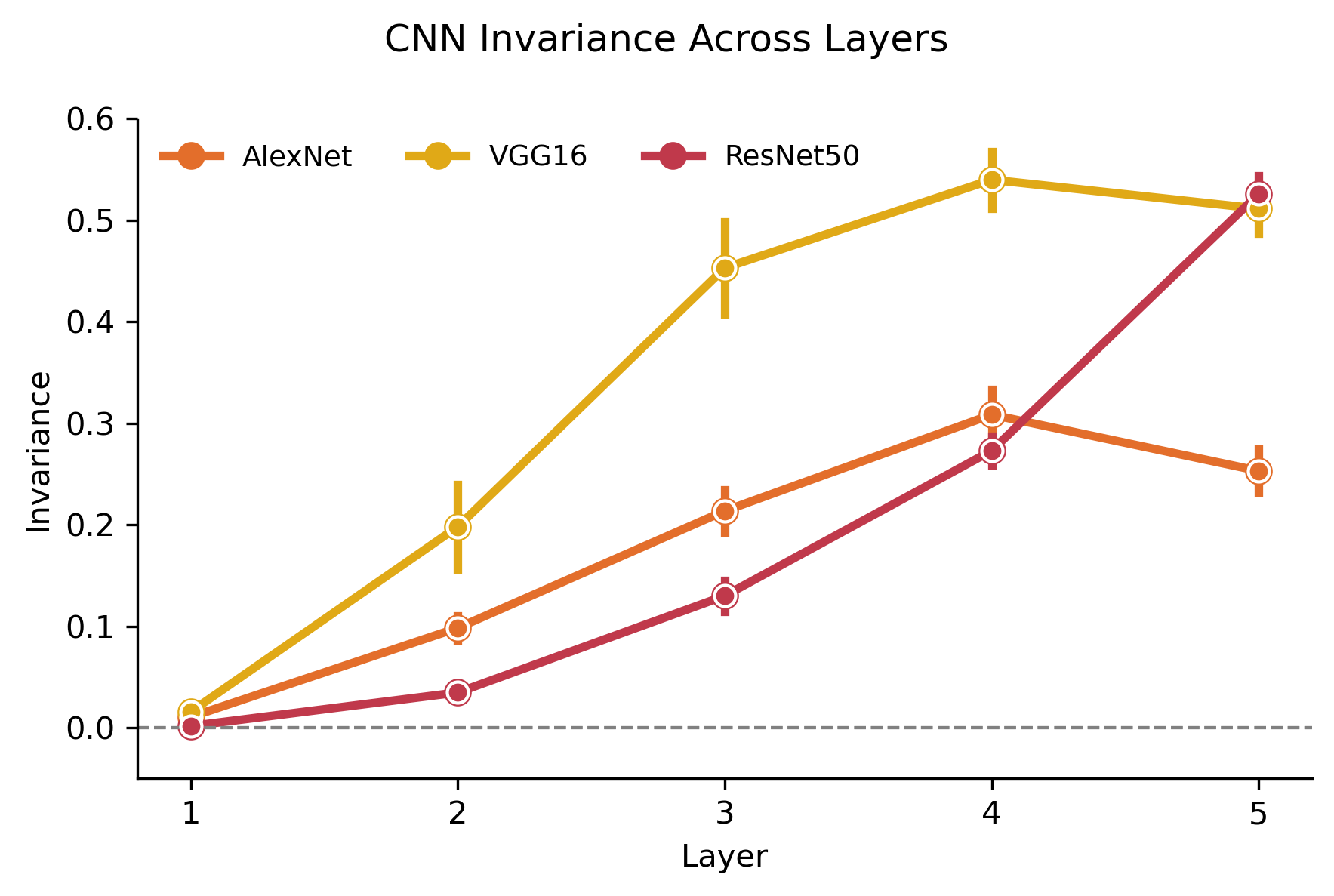
- CNNs show monotonic invariance buildup. VGG16 and ResNet50 reach peak invariance of ~0.52–0.54; AlexNet plateaus much lower (~0.26), consistent with its shallower feature hierarchy.
Pipeline
- Feature extraction — hidden states from every layer (CLS tokens, mean-pooled patch tokens for ViTs; pooled feature maps for CNNs)
- Correlation matrix — 32×32 pairwise Pearson correlations per layer
- Invariance quantification — within- vs. between-category correlation differences
Contributors
Fengtong (Farah) Du (implementation) · Miguel Angel Nunez Ochoa (invariance metric design)