Audio–Visual Integration Model (AVIM) for Continual Learning
AVIM is a multimodal spiking model that fuses visual and audio inputs and learns with a Synaptic Tagging & Capture–like rule. It targets brain-inspired continual learning with reduced catastrophic forgetting.
Abstract
We introduce an Audio–Visual Integration Model (AVIM) implemented in a spiking neural network. Visual features (from a compact CNN) and audio codes (Randomized Near-Orthogonal Sparse Codes, NOSC) are integrated in a multi-layer SNN. Learning uses a calcium-based Synaptic Tagging & Capture (STC) mechanism that consolidates useful changes while acquiring new classes, supporting continual learning without heavy rehearsal. We evaluate on MNIST/EMNIST/CIFAR-10/100 under class-incremental protocols and analyze stability–plasticity behavior and representational dynamics.
Summary
- Biophysically grounded SNN — AVIM is built from multi-compartment Hodgkin–Huxley neurons, aligning the computation with cortical biophysics. :contentReferenceoaicite:1
- Calcium-based STC learning — We implement Synaptic Tagging & Capture as the core plasticity rule, linking tags and PRPs to support consolidation while learning new classes. :contentReferenceoaicite:2
- Brain-inspired continual-learning paradigm — The paper formalizes a paradigm meant to approximate human lifelong learning and uses it to evaluate models. :contentReferenceoaicite:3
- SOTA vs. CL baselines — AVIM outperforms OWM, iCaRL, and GEM, and forms stable representations over time. :contentReferenceoaicite:4
Model
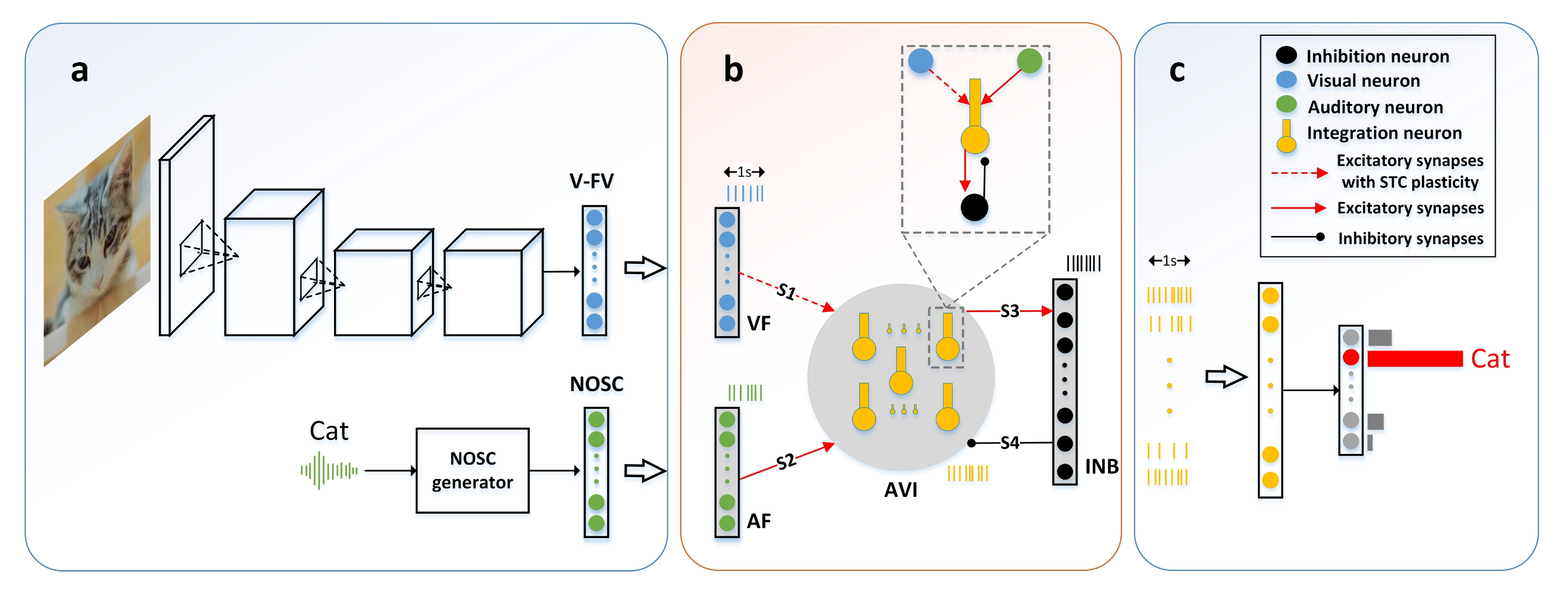
- Inputs
- Visual: a compact CNN produces a visual feature vector (V-FV).
- Audio: a Randomized Near-Orthogonal Sparse Code (NOSC) encodes the audio stream.
- Visual: a compact CNN produces a visual feature vector (V-FV).
- Spiking core
- Multi-compartment HH neurons with calcium-based STC implement tagging and protein-capture dynamics for consolidation. :contentReferenceoaicite:5
- Multi-compartment HH neurons with calcium-based STC implement tagging and protein-capture dynamics for consolidation. :contentReferenceoaicite:5
- Integration & readout
- Layers L1/L2 represent visual/audio streams; L3 integrates; L4 provides inhibition.
- A lightweight LOC-ANN reads out class labels from firing patterns (as in the poster schematic).
- Layers L1/L2 represent visual/audio streams; L3 integrates; L4 provides inhibition.
Continual-learning setup
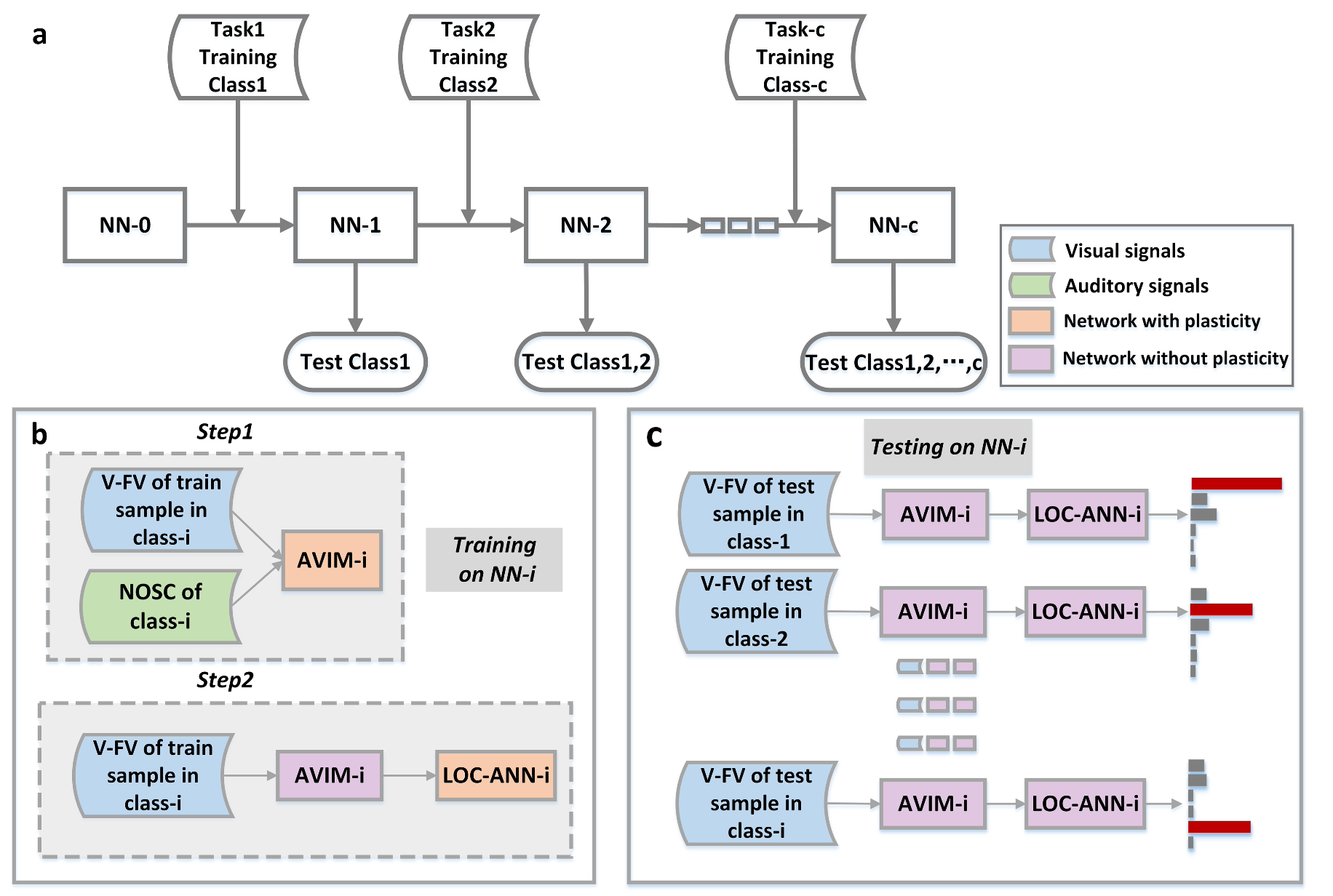
- Scenario: class-incremental sequences without (or with minimal) rehearsal, matching the proposed paradigm. :contentReferenceoaicite:6
- Benchmarks: MNIST, EMNIST, CIFAR-10/100.
- Metrics: average accuracy, forgetting, stability–plasticity balance.
Results
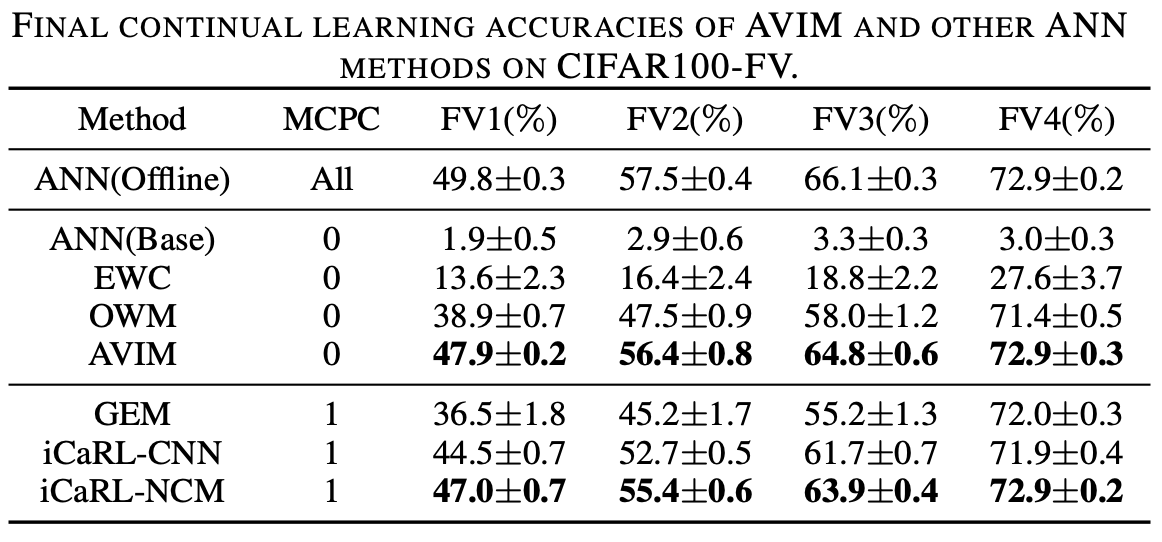
- SOTA performance & stable representations under the new paradigm, beating OWM/iCaRL/GEM on representative tasks. :contentReferenceoaicite:7
- Qualitative stability: learned object representations remain stable as new classes are acquired. :contentReferenceoaicite:8
Reference
Chen, W., Du, F., Wang, Y., & Cao, L. A Biologically Plausible Audio-Visual Integration Model for Continual Learning. arXiv:2007.08855 (IJCNN 2021).